LU Decomposition
Summary
LU Decomposition is an example of how to use Nu+ features to optimize an algorithm, using multithreaded and vectorial code.
Reusable code decomposition and multithreaded and vectorial optimization methods are shown; they can be applied to every other parallelizable algorithm, from image processing to machine learning ones.
Algorithm Description
LU Decomposition is used in solving systems of linear equations
Algorithm decomposes A in:
-
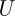 upper triangolar matrix
upper triangolar matrix -
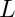 lower triangolar matrix
lower triangolar matrix
Partial Pivoting
Partial pivoting is an optimization of standard LU Decomposition that aims to reduce numerical instability
- Therefore a matrix
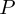 is needed to keep track of pivoting operations
is needed to keep track of pivoting operations - Partial because pivoting is applied on rows only
These matrices have to verify the relation:
Algorithm Usage
LU decomposition with pivoting is used in linear systems solving, considering that:
Multiplying by x:
Considering that:
Then:
Defining:
Then:
In order to solve the linear system, we need to solve:
- Firstly
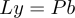 for y
for y - Then
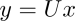 for x
for x
The advantage is that we can solve the first linear system using forward substitution and the second one using back substitution, that is much faster than solving the original system (whose A matrix isn't always triangular).
Pseudocode

nu+ Optimization
In this section, it is shown how the pseudo-code algorithm can be optimized using nu+ features.
Pivoting phase
The pivoting phase has been made multi-threaded. Every k-th iteration (k ranging from 0 to m-1) of the pivoting operations works on the elements belonging to the k-th column and to rows from k to m-1.
Less rows than threads
In this case rows are less than threads, the algorithm disables the exceeding threads and enables only the number of threads equal to rows
if (rowsTreated < THREADS) {
if(id<rowsTreated-1)
{
v[id] = u[k+id][k];
__builtin_nuplus_flush((int)&v[id]);
}
A following barrier make disabled threads wait for working threads.
Rows are multiple of threads
Every thread is enabled, working on a number of rows defined by work_per_thread variable
work_per_thread = rowsTreated / THREADS;
if (rowsTreated % THREADS == 0) {
for(int i=0; i<work_per_thread; i++)
{
v[k+id*work_per_thread+i] = u[k+id*work_per_thread+i][k];
__builtin_nuplus_flush((int)&v[k+id*work_per_thread+i]);
}
Rows are not multiple of threads
Every thread is enabled, making at least "work_per_thread" operation. Last thread (identified by the greatest thread_id) makes "extra_work" more operations.
extra_work = work_per_thread % THREADS;
for(int i=0; i<work_per_thread + (id==THREADS-1) * extra_work; i++)
{
v[k+id*work_per_thread+i] = u[k+id*work_per_thread+i][k];
__builtin_nuplus_flush((int)&v[k+id*work_per_thread+i]);
}
If Threads with id less than the maximum will complete their operations before the maximum id one they wait for its completion in next barrier.
Row exchanging phase
For row exchaning phase, both multithreading and vectorialization has been used.
Multithreading in row exchanging
Multithreading row-exchanging has been made possible by creating an ad-hoc data structure: a vector containing pointers to matrices.
This way threads can access in the same cycle to own matrix using their own id and making the programmer sure that no access conflict can happen.
vec16f32 vector_k_th = vectorialize(vom[id][k]);
vec16f32 vector_pivot_th = vectorialize(vom[id][piv]);
vom is "vector of matrices" and every thread access to one ad one only matrix identified by own id.
Vectorialization
Row exchanges make use of vector built-ins and mask register operation.
Rows are temporarily stored in vector variables.
vec16f32 vector_k_th = vectorialize(vom[id][k]); vec16f32 vector_pivot_th = vectorialize(vom[id][piv]); vec16f32 bufferVector = vector_k_th;
First, a mask-register writing allows only the desired elements to be exchanged.
vec16i32 mask = createVectorMask(k);
__builtin_nuplus_write_mask_regv16i32(mask);
vec16f32 createVectorMask (int k)
{
vec16f32 mask = __builtin_nuplus_makevectori32(0);
for (int i= (id==0)*k; i<(id%2==0)*SIZE + (id==1)*(k-1); i++)
{
mask[i] = -1;
}
return mask;
}
Then the k-th vector row is exchanged with the pivot-th one.
vector_k_th = vector_pivot_th;
vector_pivot_th = bufferVector;
Vector variables are then de-vectorialized and their elements stored in the original locations.
devectorialize(vector_k_th,k);
devectorialize(vector_pivot_th,piv);
Rows are saved in memory.
Mask-register is reset, enabling all lanes.
void restoreVectorMask()
{
__builtin_nuplus_write_mask_regv16i32(__builtin_nuplus_makevectori32(-1));
}
Built-ins usage
Even if LU decomposition kernel is not too complex, it was required to use several nu+ built-ins for different purposes.
- Flush
This built-in is needed when it is necessary to store a variable in memory. If flush wasn’t used, computations would have effects on core caches only.
- Barriers
Barriers allow the programmer to synchronize threads executions. As instance, when performing operations on 𝐿 and 𝑈 at the end of each iteration, other threads shall no start pivoting or rows-exchanging phase, because they would work on non-updated matrices. With barrier built-in it is possible forcing threads to wait for job completion of other ones.
- Mask register writing
Using this intrinsic it is possible activate or deactivate hardware lanes, i.e. performing row exchanging only on some elements, not for all the row