Difference between revisions of "LU Decomposition"
(→Pseudocode) |
(→= Rows are not multiple of threads) |
||
| Line 73: | Line 73: | ||
| − | === Rows are not multiple of threads == | + | === Rows are not multiple of threads === |
Every thread is enabled, making at least "work_per_thread" operation. Last thread (identified by the greatest thread_id) makes "extra_work" more operations. | Every thread is enabled, making at least "work_per_thread" operation. Last thread (identified by the greatest thread_id) makes "extra_work" more operations. | ||
Revision as of 20:16, 2 February 2018
Contents
Summary
LU Decomposition is an example of how to use Nu+ features to optimize an algorithm, using multithreaded and vectorial code.
Reusable code decomposition and multithreaded and vectorial optimization methods are shown; they can be applied to every other parallelizable algorithm, from image processing to machine learning ones.
Algorithm Description
LU Decomposition is used in solving systems of linear equations
Algorithm decomposes A in:
-
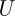 upper triangolar matrix
upper triangolar matrix -
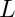 lower triangolar matrix
lower triangolar matrix
Partial Pivoting
Partial pivoting is an optimization of standard LU Decomposition that aims to reduce numerical instability
- Therefore a matrix
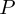 is needed to keep track of pivoting operations
is needed to keep track of pivoting operations - Partial because pivoting is applied on rows only
These matrices have to verify the relation:
Pseudocode

nu+ Optimization
In this section, it is shown how the pseudo-code algorithm can be optimized using nu+ features.
Pivoting phase
The pivoting phase has been made multi-threaded. Every k-th iteration (k ranging from 0 to m-1) of the pivoting operations works on the elements belonging to the k-th column and to rows from k to m-1.
Less rows than threads
In the case rows are less than threads, the algorithm disables the exceeding threads and enables only as many threads as rows.
if (rowsTreated < THREADS) {
if(id<rowsTreated-1)
{
v[id] = u[k+id][k];
__builtin_nuplus_flush((int)&v[id]);
}
A following barrier make disabled threads wait for working threads.
Rows are multiple of threads
Every thread is enabled, working on a number of rows defined by work_per_thread variable
work_per_thread = rowsTreated / THREADS;
if (rowsTreated % THREADS == 0) {
for(int i=0; i<work_per_thread; i++)
{
v[k+id*work_per_thread+i] = u[k+id*work_per_thread+i][k];
__builtin_nuplus_flush((int)&v[k+id*work_per_thread+i]);
}
Rows are not multiple of threads
Every thread is enabled, making at least "work_per_thread" operation. Last thread (identified by the greatest thread_id) makes "extra_work" more operations.
extra_work = work_per_thread % THREADS;
for(int i=0; i<work_per_thread + (id==THREADS-1) * extra_work; i++)
{
v[k+id*work_per_thread+i] = u[k+id*work_per_thread+i][k];
__builtin_nuplus_flush((int)&v[k+id*work_per_thread+i]);
}
Threads with id less than the maximum will complete their operations before the maximum id one, and will wait for its completion in next barrier.